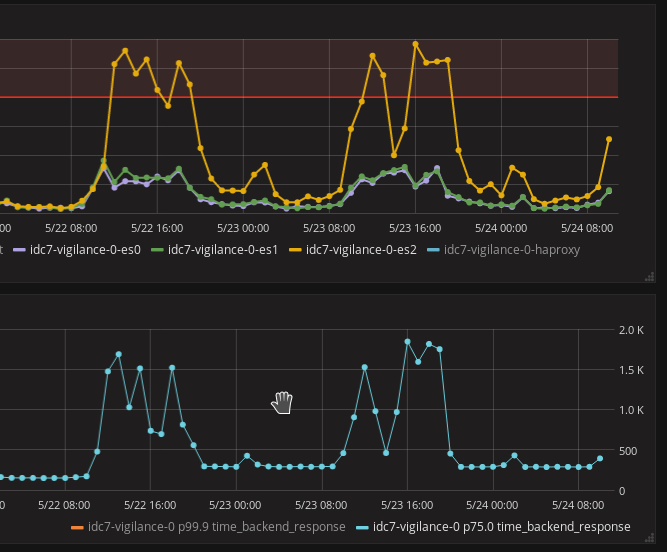
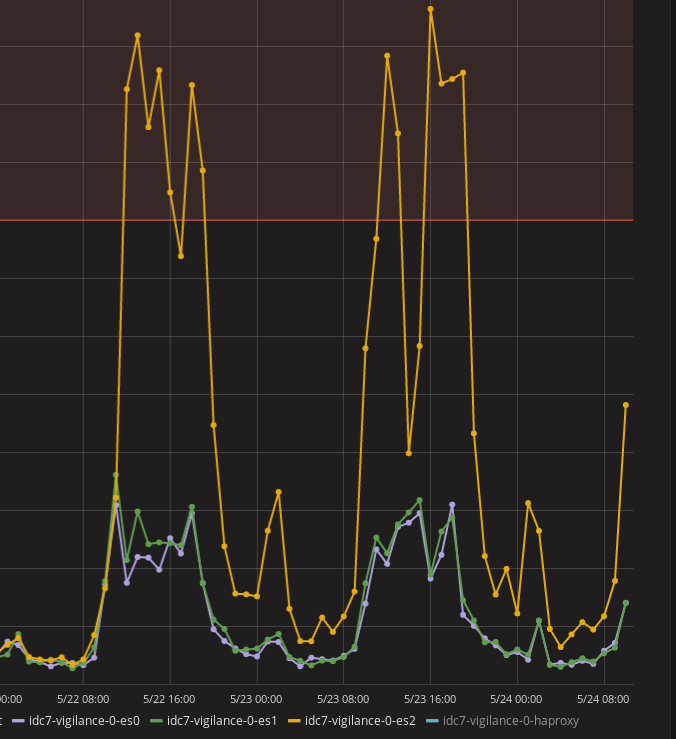
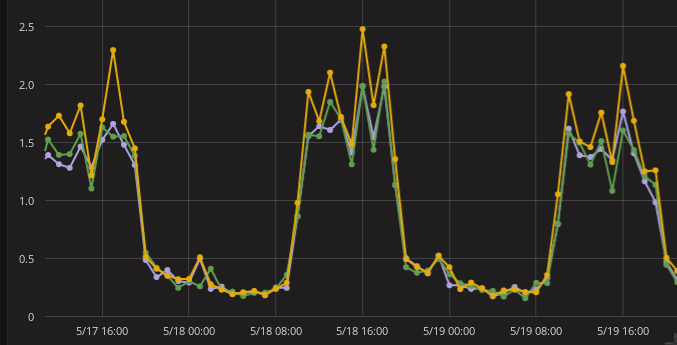
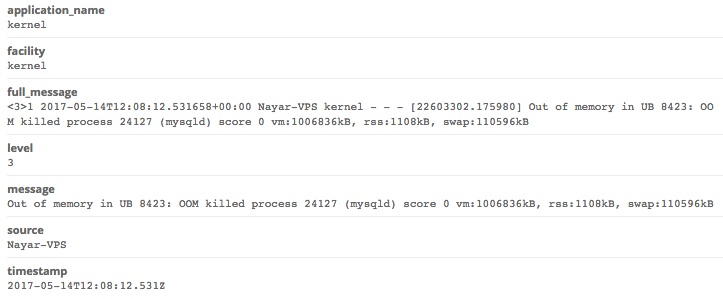
During normal usage, we got no loss of information on our Elasticsearch cluster. It was about 200 entries per second. We stressed tested the platform by doing bulks inserts at 7000 entries/s. We started seeing data getting lost.
It seems like the date format is not valid but the code has not been changed and there are no if-else statement where there could have been a possibility of echoing the datetime using a different branch. We are returning the time by the python function `datetime.isoformat(‘ ‘)`. Why would the same line of code produce 2 different outputs under heavy stress?
[2017-05-30T15:03:30,562][DEBUG][o.e.a.b.TransportShardBulkAction] [idc7-citadelle-0-es0] [proxydns-2017-05-30][0] failed to execute bulk item (index) BulkShardRequest [[proxydns-2017-05-30][0]] containing [1353] requests
org.elasticsearch.index.mapper.MapperParsingException: failed to parse [date.date_answer]
at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:298) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseObjectOrField(DocumentParser.java:450) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseValue(DocumentParser.java:576) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.innerParseObject(DocumentParser.java:396) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseObjectOrNested(DocumentParser.java:373) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseObjectOrField(DocumentParser.java:447) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseObject(DocumentParser.java:467) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.innerParseObject(DocumentParser.java:383) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseObjectOrNested(DocumentParser.java:373) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.internalParseDocument(DocumentParser.java:93) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentParser.parseDocument(DocumentParser.java:66) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DocumentMapper.parse(DocumentMapper.java:277) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.shard.IndexShard.prepareIndex(IndexShard.java:532) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.shard.IndexShard.prepareIndexOnPrimary(IndexShard.java:509) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.bulk.TransportShardBulkAction.prepareIndexOperationOnPrimary(TransportShardBulkAction.java:447) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.bulk.TransportShardBulkAction.executeIndexRequestOnPrimary(TransportShardBulkAction.java:455) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.bulk.TransportShardBulkAction.executeBulkItemRequest(TransportShardBulkAction.java:143) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.bulk.TransportShardBulkAction.shardOperationOnPrimary(TransportShardBulkAction.java:113) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.bulk.TransportShardBulkAction.shardOperationOnPrimary(TransportShardBulkAction.java:69) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryShardReference.perform(TransportReplicationAction.java:939) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryShardReference.perform(TransportReplicationAction.java:908) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.ReplicationOperation.execute(ReplicationOperation.java:113) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$AsyncPrimaryAction.onResponse(TransportReplicationAction.java:322) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$AsyncPrimaryAction.onResponse(TransportReplicationAction.java:264) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$1.onResponse(TransportReplicationAction.java:888) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$1.onResponse(TransportReplicationAction.java:885) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.shard.IndexShardOperationsLock.acquire(IndexShardOperationsLock.java:147) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.shard.IndexShard.acquirePrimaryOperationLock(IndexShard.java:1654) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction.acquirePrimaryShardReference(TransportReplicationAction.java:897) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction.access$400(TransportReplicationAction.java:93) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$AsyncPrimaryAction.doRun(TransportReplicationAction.java:281) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryOperationTransportHandler.messageReceived(TransportReplicationAction.java:260) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryOperationTransportHandler.messageReceived(TransportReplicationAction.java:252) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.transport.RequestHandlerRegistry.processMessageReceived(RequestHandlerRegistry.java:69) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.transport.TransportService$7.doRun(TransportService.java:618) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:613) [elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-5.3.0.jar:5.3.0]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [?:1.8.0_121]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [?:1.8.0_121]
at java.lang.Thread.run(Thread.java:745) [?:1.8.0_121]
Caused by: java.lang.IllegalArgumentException: Invalid format: "2017-05-30 13:03:11" is too short
at org.joda.time.format.DateTimeParserBucket.doParseMillis(DateTimeParserBucket.java:187) ~[joda-time-2.9.5.jar:2.9.5]
at org.joda.time.format.DateTimeFormatter.parseMillis(DateTimeFormatter.java:826) ~[joda-time-2.9.5.jar:2.9.5]
at org.elasticsearch.index.mapper.DateFieldMapper$DateFieldType.parse(DateFieldMapper.java:242) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.DateFieldMapper.parseCreateField(DateFieldMapper.java:462) ~[elasticsearch-5.3.0.jar:5.3.0]
at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:287) ~[elasticsearch-5.3.0.jar:5.3.0]
... 40 more
It turns out that during stress tests, logs with a wider range of timestamps will be produced. Lemme illustrate it using this little python script for example.
import datetime
lol = datetime.datetime.fromtimestamp(1496211943.123)
print lol.isoformat(' ') # 2017-05-31 10:25:43.123000
lol = lol + datetime.timedelta(milliseconds=500) # we add 500 milliseconds to it.
print lol.isoformat(' ') # 2017-05-31 10:25:43.623000
lol = lol - datetime.timedelta(milliseconds=623) # we substract 623 milliseconds. What will the result be?
print lol.isoformat(' ') # 2017-05-31 10:25:43
Noticed how the format changed? I was expecting the output to be `2017-05-31 10:25:43.000000`. During normal usage, it is highly unlikely for someone to do requests at exactly 0 milliseconds. Even if they did, the data loss would be very little and non-detectable. By doing the stress test, what was very improbable become more probable. We detected it.
But why did the stupid format had to change? Reading the official documentation of the datetime library of python, it saw this:
datetime.isoformat([sep])
Return a string representing the date and time in ISO 8601 format, YYYY-MM-DDTHH:MM:SS.mmmmmm or, if microsecond is 0, YYYY-MM-DDTHH:MM:SS [1]
Why did they choose to do this? No idea. Anyways, I resorted to write my own format of which I would be sure not to have this problem again.
print lol.strftime('%Y-%m-%d %H:%M:%S.%f')
[1] https://docs.python.org/2/library/datetime.html