My Asus Zenbook UX310UQ which I bought in 2018 served me very well except in 1 department: battery life. Recently, the battery would just die randomly so I had to keep it plugged in at all times. So I needed a laptop with adequate battery so that I can work on the move or even be my sofa.
I was deciding between an Asus Zenbook 14″ OLED (which has a gorgeous display) and a Macbook Air with the M1 chip. It was about Rs 10,000 cheaper than the Macbook with similar specs.
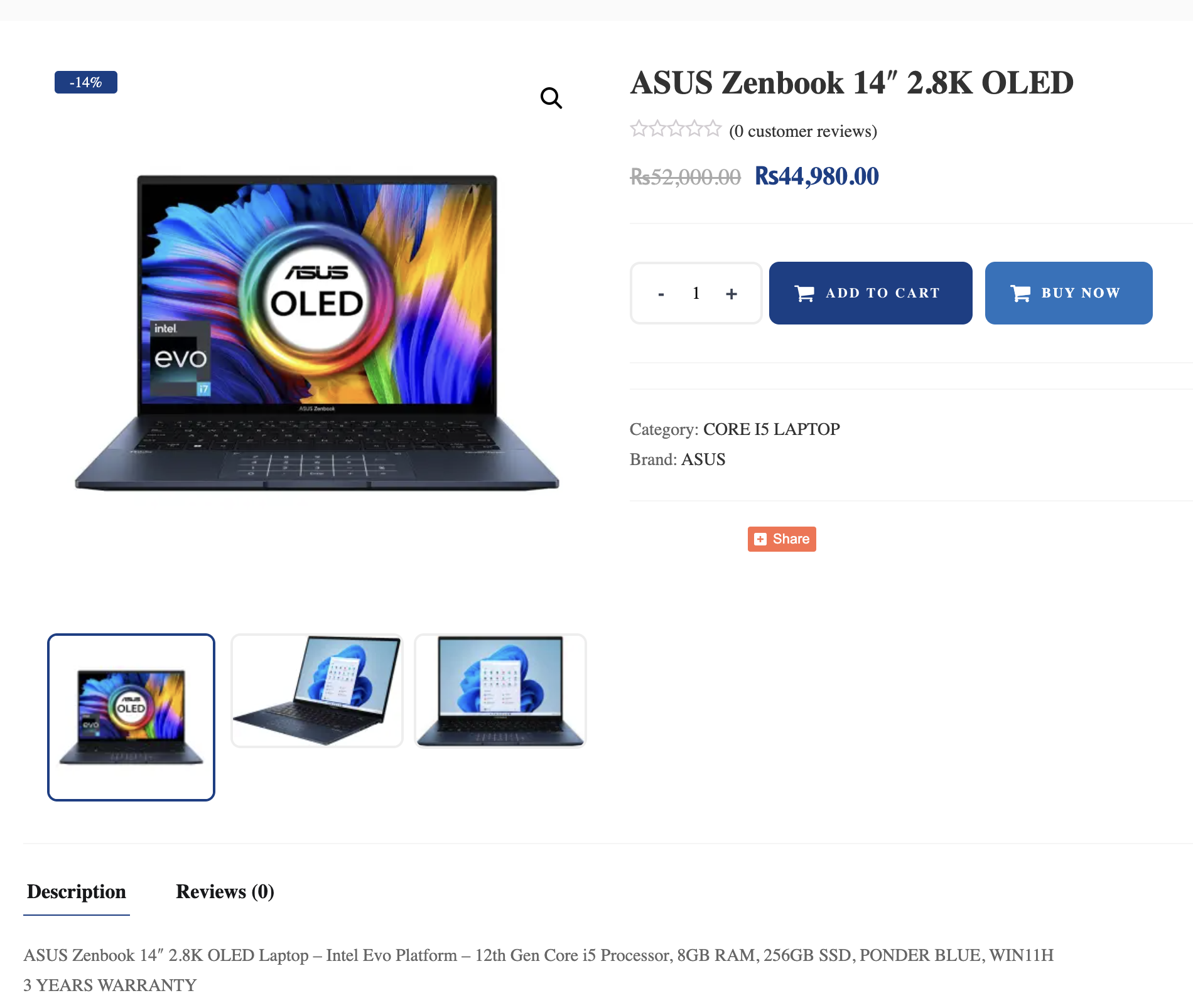
The RAMs cannot be upgraded on both laptops unfortunately and 8GB is very limit in 2023. I decided to opt for the Macbook M1 specially after hearing excellent reviews about the battery life and performance.
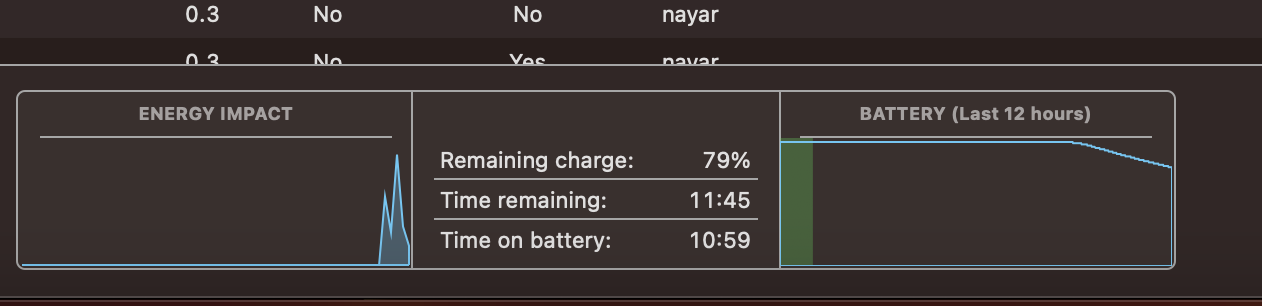
It really didn’t disappoint in that area. I got 8 hours of battery life in the first day and I even run some machine learning codes on it. However 256GB of storage is really limiting. Every time I would install a software, it would bring me anxiety about filling the disk. The 8GB Ram honestly “feels” more than adequate for web browsing and even coding. However it would swap to the SSD a lot in the background which is rumoured to cause damage to it. Since everything is soldered to the board, replacing the SSD will not be possible thus the Macbook might be bricked earlier than expected. I haven’t found lots of people actually reporting dead M1 SSDs on forums. Please share if you find some with me.
I was quite surprised to discover that the laptop can be used without signup with an Apple account. The OS even updates without it. However in order to update Apple apps such as Numbers, iMovie etc from the App store, you will need to signin using an Apple ID.
The MacOS is really nice in terms of keeping your screen real estate. The window borders are virtually inexistent. On my KDE laptop, so much pixels were wasted to draw the borders. 
The widgets feels much more luxurious than on KDE. Is it the better screen or just better graphics. I don’t know

And 1 thing which really impressed me was whenever you open the lid, the laptop is ready to be used. My Linux laptop would take like 5-10 seconds to be ready from sleep.
Some cons:
- No print screen button
- SSHFS is really slow. I got like 3MB/s. https://osxfuse.github.io/
- Python/git stop working after update
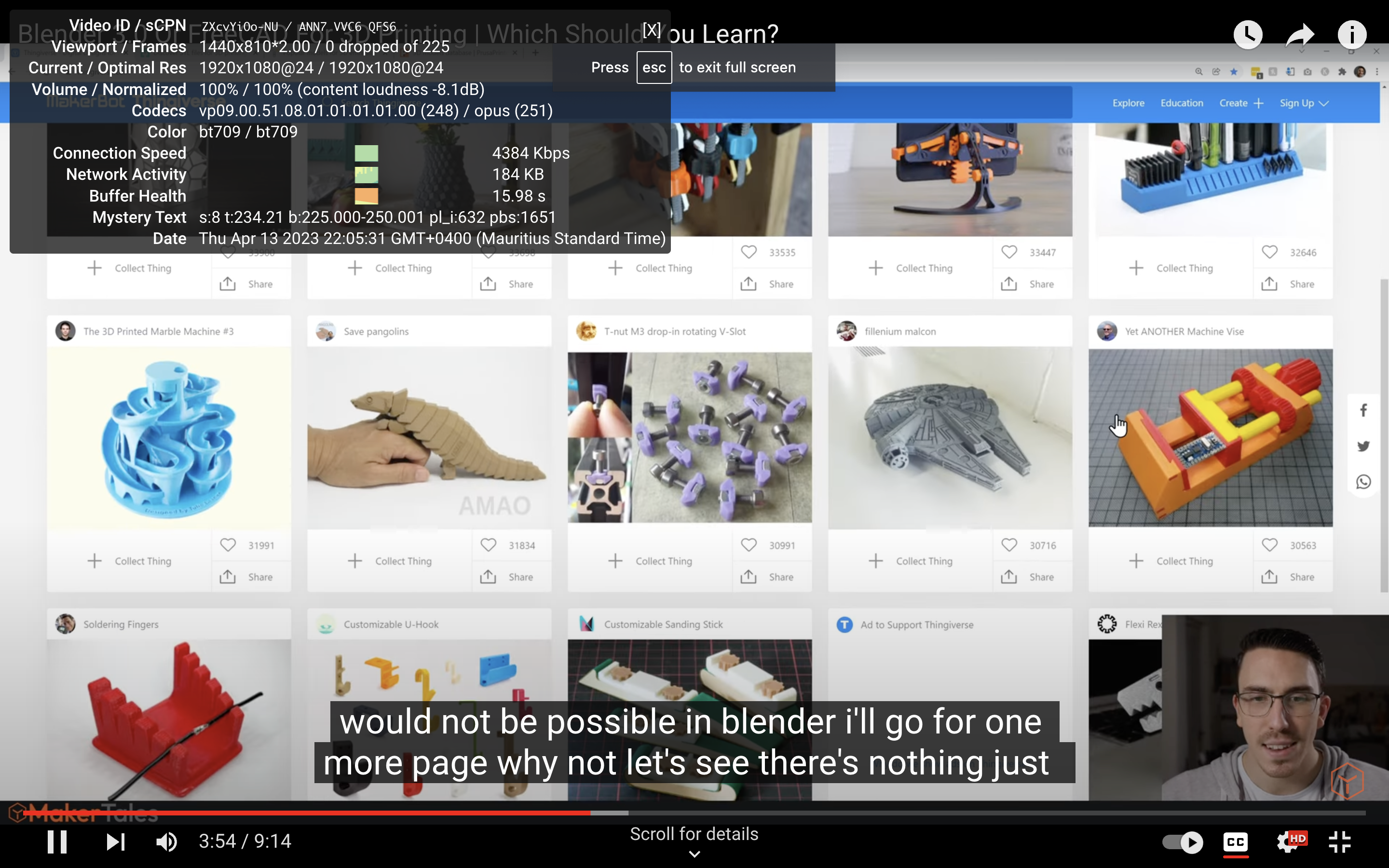
- Youtube was not playing in full HD. I could see the blurriness
- You get only 1 year warranty as compared to 3 on the ASUS
- Every one has a Macbook in a cafe. I had to place a sticker to recognise mine.

After 1 year of using it, I had to upgrade to a more powerful one since the M1 Air is not really built to run large language models on them. So I sold it to my sister who I hope will take care of it 🙂